Abstract
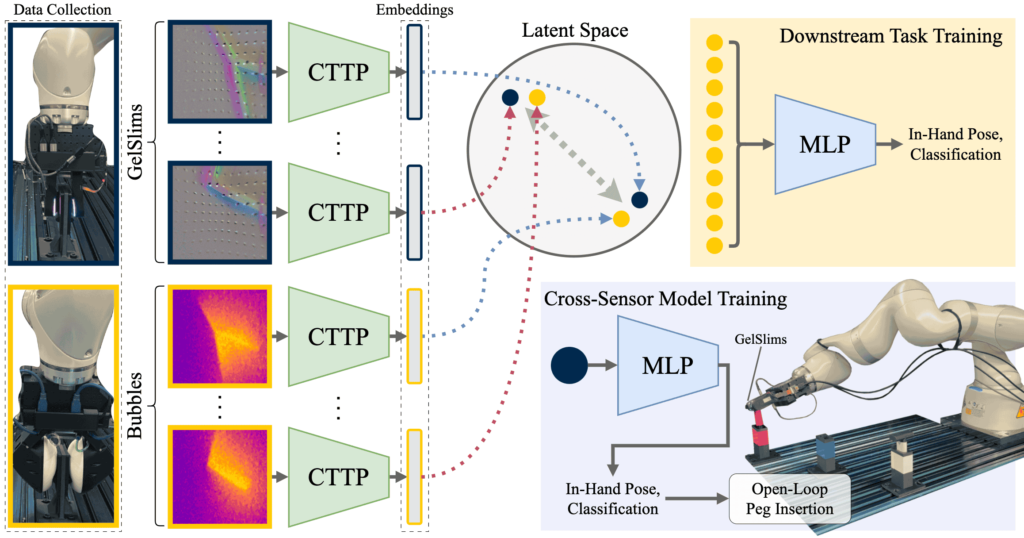
Tactile sensors differ greatly in design, making it challenging to develop general-purpose methods for processing tactile feedback. In this paper, we introduce a contrastive self-supervised learning approach that represents tactile feedback across different sensor types. Our method utilizes paired tactile data—where two distinct sensors, in our case Soft Bubbles and GelSlims, grasp the same object in the same configuration—to learn a unified latent representation. Unlike current approaches that focus on reconstruction or task-specific supervision, our method employs contrastive learning to create a latent space that captures shared information between sensors. By treating paired tactile signals as positives and unpaired signals as negatives, we show that our model effectively learns a rich, sensor-agnostic representation. Despite significant differences between Soft Bubble and GelSlim sensors, the learned representation enables strong downstream task performance, including zero-shot classification and pose estimation. This work provides a scalable solution for integrating tactile data across diverse sensor modalities, advancing the development of generalizable tactile representations.
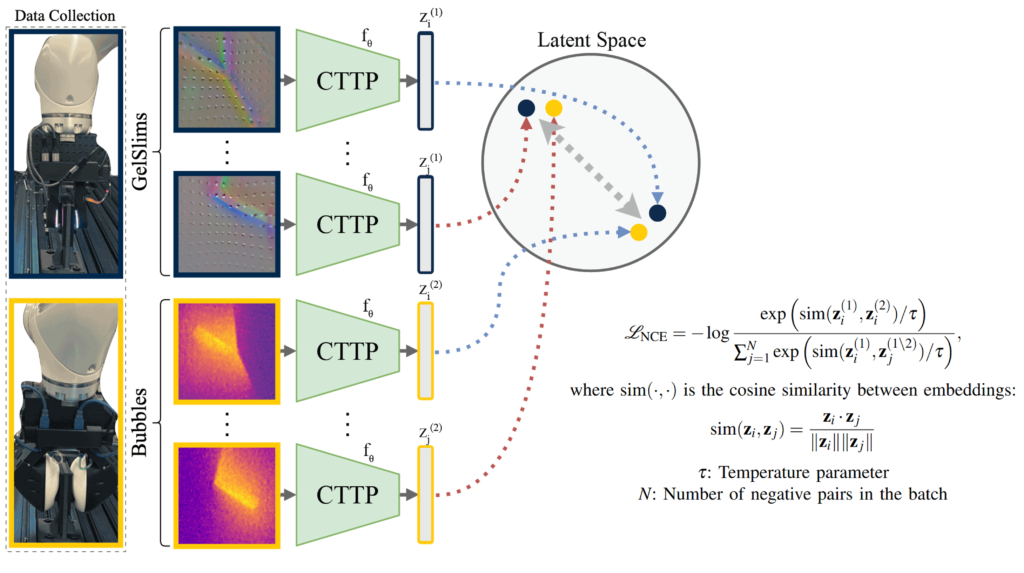
Method
The objective of contrastive learning is to learn an embedding function fθ that minimizes the distance of latent vectors between positive pairs, while maximizing the distance between negative. We use InfoNCE loss to optimize for this objective.
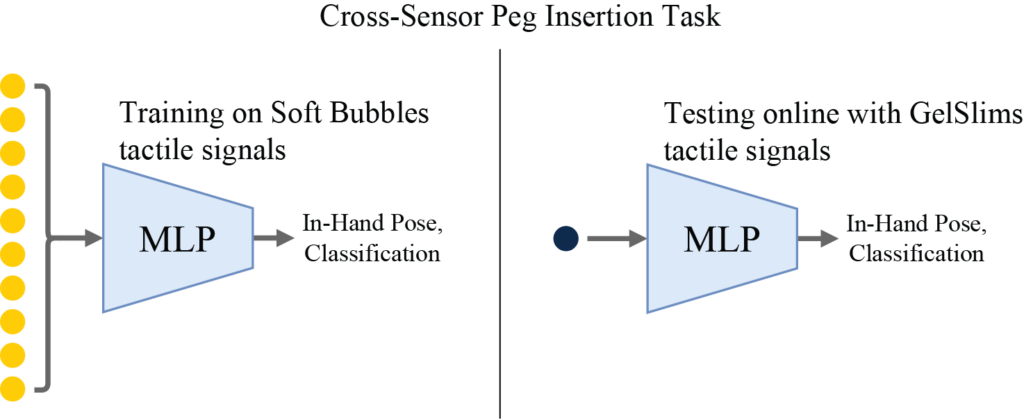
Robot Experiments
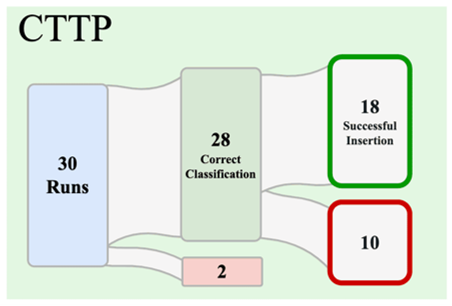
We use trained In-Hand Pose estimation and tool classification models, originally developed using Soft Bubbles’ latent space, to test GelSlims’ signals in a peg insertion task (zero-shot ).
Setup
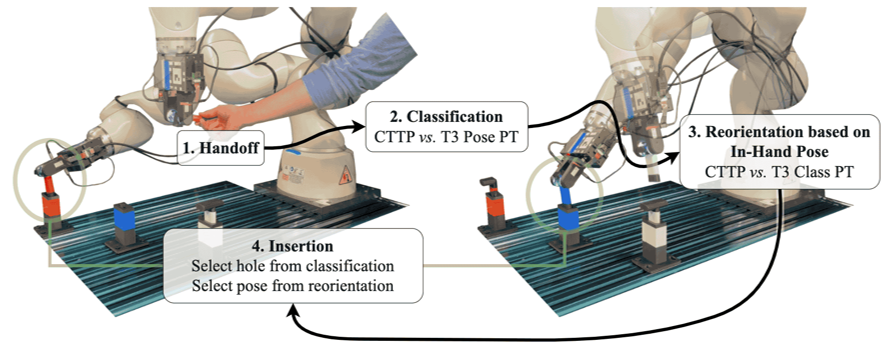
Results