Abstract
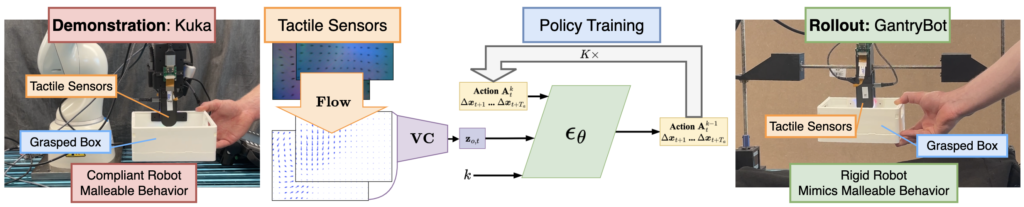
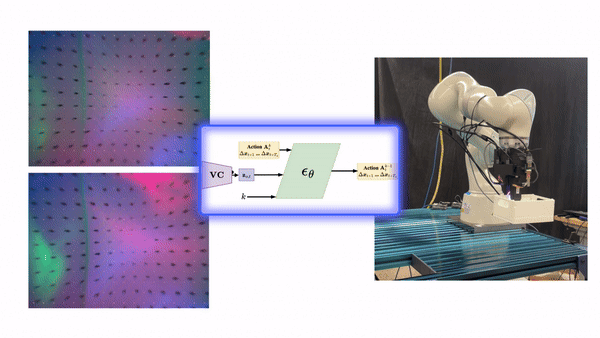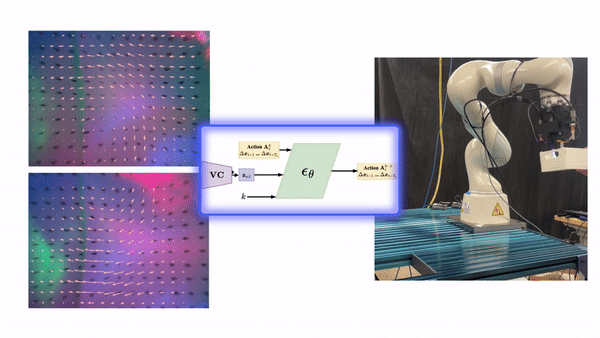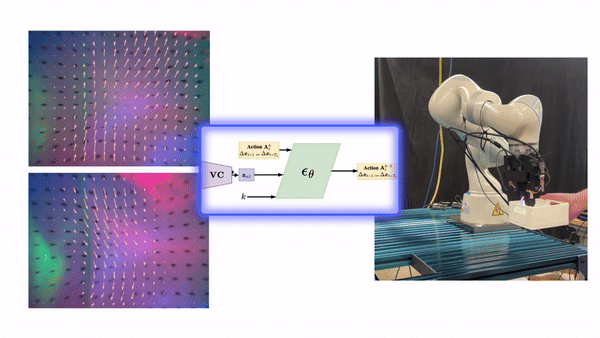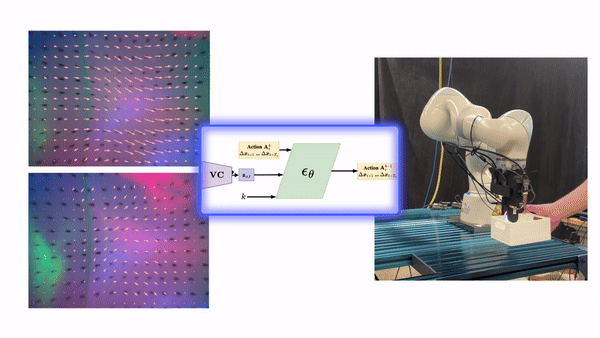
Tactile sensing is a powerful means of implicit communication between a human and a robot assistant. In this paper, we investigate how tactile sensing can transcend cross-embodiment differences across robotic systems in the context of collaborative manipulation. Consider tasks such as collaborative object carrying where the human-robot interaction is force rich. Learning and executing such skills requires the robot to comply to the human and to learn behaviors at the joint-torque level. However, most robots do not offer this compliance or provide access to their joint torques. To address this challenge, we present an approach that uses tactile sensors to transfer policies from robots with these capabilities to those without. We show how our method can enable a cooperative task where a robot and human must work together to maneuver objects through space. We first demonstrate the skill on an impedance control capable robot equipped with tactile sensing, then show the positive transfer of the tactile policy to a planar prismatic robot that is only capable of position control and does not come equipped with any sort of force/torque feedback yet is able to comply to the human motions only using tactile feedback.
Animated Videos




Architecture Details
Chi et al. [1] tested two architectures for diffusion-based behavior cloning, a convolutional neural network (CNN) and a transformer-based architecture. They noted that the CNN architecture may require less hyperparameter tuning, and this was our reason for selecting it. We used the same 1D convolutional U-Net architecture the authors of this work present, which is visualized here:
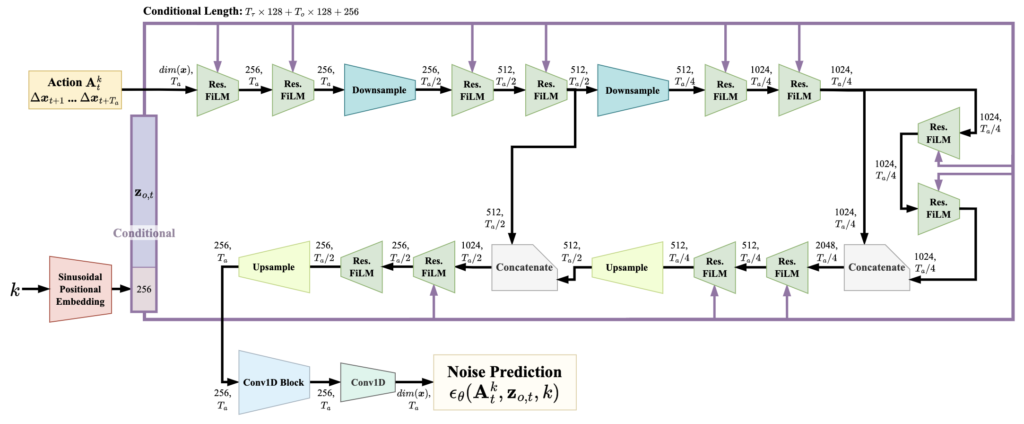
This is the noise prediction network ϵθ used in Section III-B of our paper, a 1D convolutional neural network, where the action is represented as a 1D vector in the workspace of the robot (in our case y,z) with Ta (in our case 4) channels. The length and number of channels of each step are shown. All numerical values listed are chosen by us.
To encode our tactile representations we selected a 2-layer CNN, visualized here:
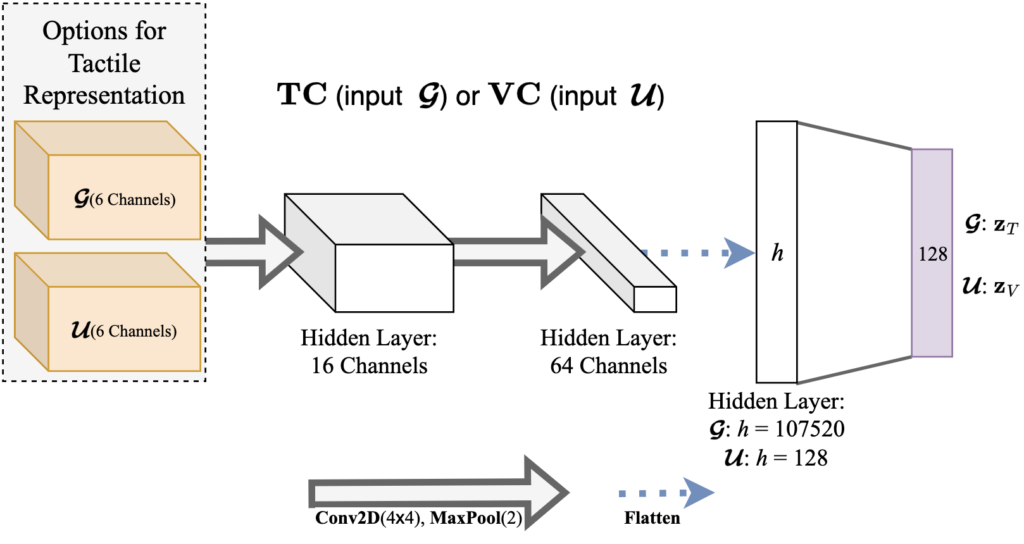
One related work showed that a few convolutional layers are sufficient to generate a robust embedding of the tactile image for force estimation [2], which is a relevant form of perception for our application. We also experimented with various standard image encoding architectures, including ResNet-18, which is a tested encoder for vision in diffusion-based behavior cloning [1], but we found this to be ineffective in encoding tactile information. We observed that standard convolution with 2 layers as we present generated a useful embedding for our application. We investigate the latent spaces of these encoders in our paper in Section V-C, these results are also shown further down on this page.
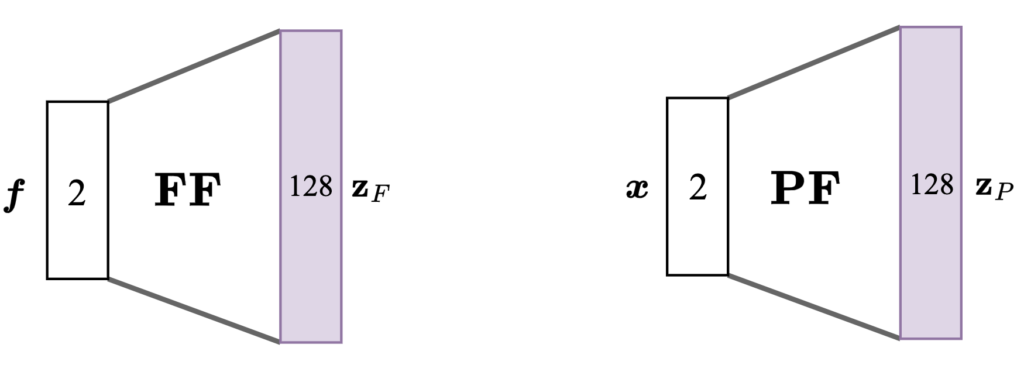
We used fully connected layers to encode the force and proprioception modalities. We make no claims as to the necessity of this, though they allow for a more expressive model should that assist in the policy learning. The dimensions of these encoding layers are shown below:
Supplementary Information
Due to space limitations in our submitted paper, there are details and images we would like to include here for your benefit. Firstly, with respect to our investigation of the latent spaces in Section V-C in our paper, we also compared the distribution of forces (without a transformation such as t-SNE, since the forces are simply two-dimensional). It seems both the forces and the shear-field representation do not suffer from the distribution shift that befalls the raw tactile images:
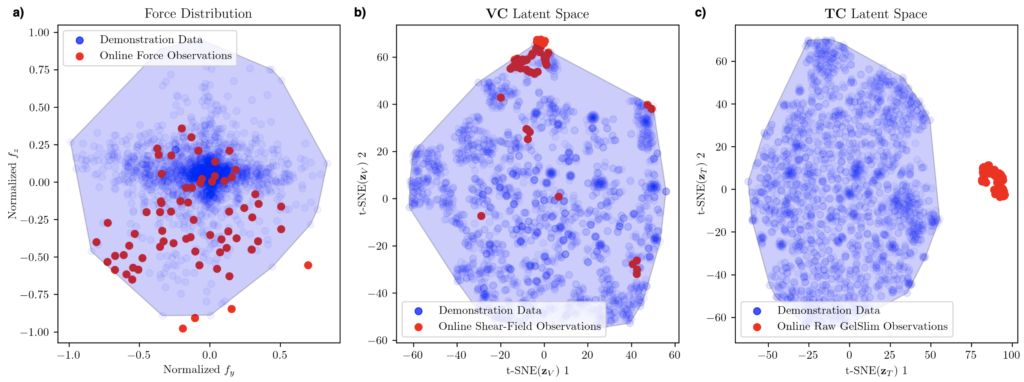
Secondly, below we box-plot the tactile-to-force estimation results we present in Table IV in our paper. The purpose of this investigation was to show the difficulty of estimating normal forces, or fx in the following figure. This figure shows the results and visualizes the architecture for force estimation for a) encoder, b) autoencoder, and c) variational autoencoder architectures:
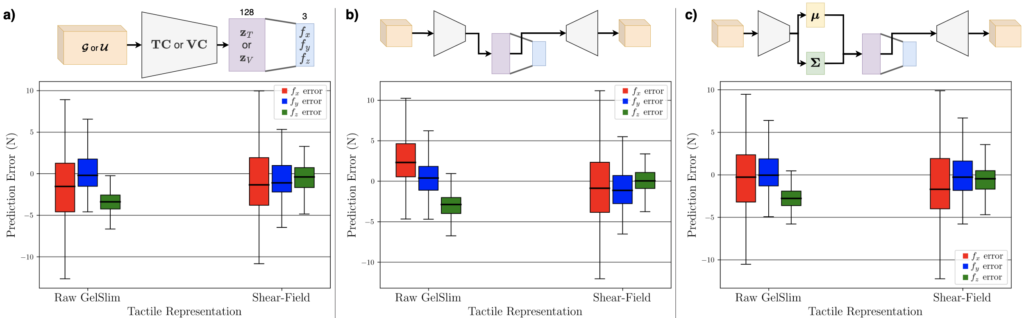
The use of the shear-field representation also exhibits improved regression in these results when compared to the raw RGB images.
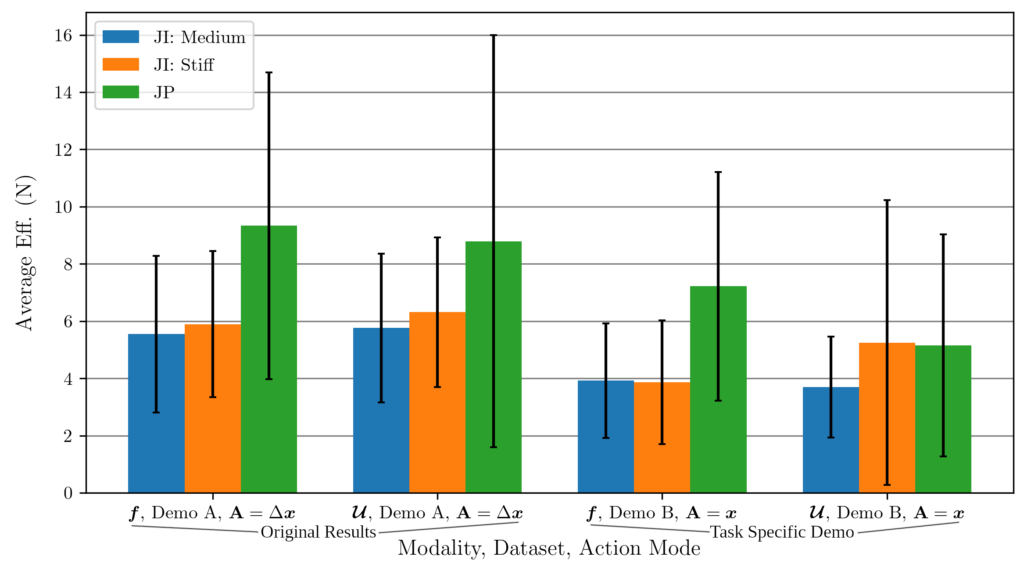
Thirdly, below are some figures that may assist in detailing the differences between the two datasets we investigate in our paper: Demo A, demonstrations of general maneuverability, and Demo B, demonstrations of the specific box placement task.

Additionally, here’s a bar graph of the results in Table III from our paper:
[1] C. Chi, S. Feng, Y. Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” in Proceedings of Robotics: Science and Systems (RSS), 2023.
[2] Z. Lu, Z. Liu, X. Zhang, Y. Liang, Y. Dong, and T. Yang, “3d force identification and prediction using deep learning based on a gelsight-structured sensor,” Sensors and Actuators A: Physical, vol. 367, p. 115036, 2024.
Paper



Submitted to the IEEE International Conference for Robotics and Automation (ICRA) 2025
Video
Code
Here we provide gelslim_shear, a python package for converting the raw tactile images into the shear-field representation that we have shown to be useful in our submitted paper.