Manipulating deformable objects is a key functionality for robotic systems. In our recent work, we’ve been thinking about how to represent deformable objects in the joint domain of vision and touch. We’ve come up with an interesting idea: using forces from touch to deform neural fields — continuous neural representations of 3D geometries (ICRA 2022 + code/dataset).
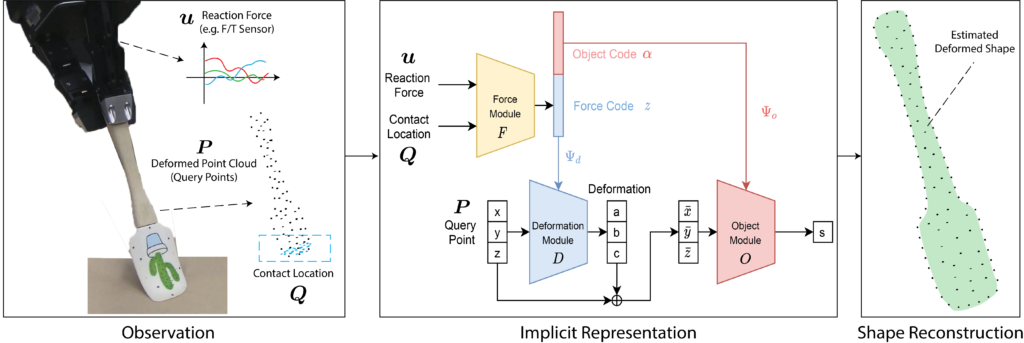
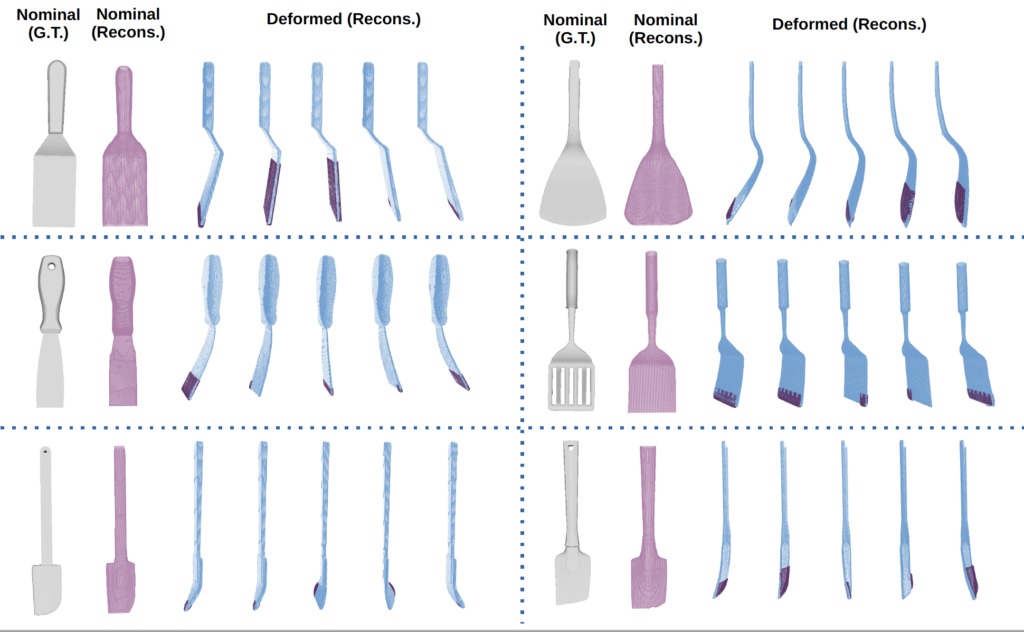
Here, we present VIRDO: an implicit, multi-modal, and continuous representation for deformable-elastic objects. VIRDO operates directly on visual (point cloud) and tactile (reaction forces) modalities and learns rich latent embeddings of contact locations and forces to predict object deformations subject to external contacts. Further, we demonstrate VIRDOs ability to: i) produce high-fidelity cross-modal reconstructions with dense unsupervised correspondences, ii) generalize to unseen contact formations, and iii) state-estimation with partial visio-tactile feedback.
A key feature of our representation is its multimodality, where we are seamlessly combining sight and touch.
Video
Authors




Citation
@article{wi2022virdo,
title={Virdo: Visio-tactile implicit representations of deformable objects},
author={Wi, Youngsun and Florence, Pete and Zeng, Andy and Fazeli, Nima},
journal={arXiv preprint arXiv:2202.00868},
year={2022}
}