
Abstract
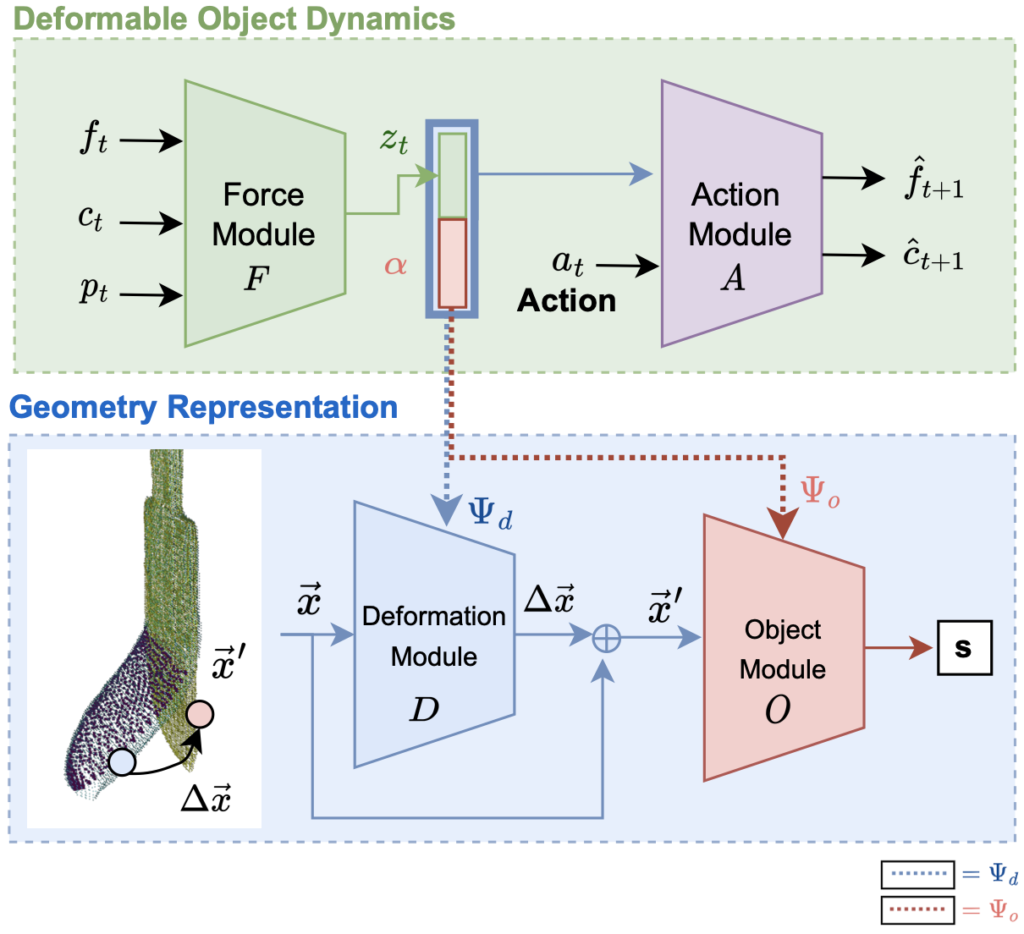
Deformable objects manipulation can benefit from representations that seamlessly integrate vision and touch while handling occlusions. In this work, we present a novel approach for, and real-world demonstration of, multimodal visuotactile state-estimation and dynamics prediction for deformable objects. Our approach, VIRDO++, builds on recent progress in multimodal neural implicit representations for deformable object state-estimation (link) via a new formulation for deformation dynamics and a complementary state-estimation algorithm that (i) maintains a belief distribution of deformation within a trajectory, and (ii) enables practical real-world application by removing the need for contact patches. In the context of two real-world robotic tasks, we show: (i) high-fidelity cross-modal state-estimation and prediction of deformable objects from partial visuo-tactile feedback, and (ii) generalization to unseen objects and contact formations.

Video
- In 6th Conference on Robotic Learning (CoRL 2022), Auckland, New Zealand (poster)
Authors




Citation
@misc{https://doi.org/10.48550/arxiv.2210.03701,
doi = {10.48550/ARXIV.2210.03701},
url = {https://arxiv.org/abs/2210.03701},
author = {Wi, Youngsun and Zeng, Andy and Florence, Pete and Fazeli, Nima},
title = {VIRDO++: Real-World, Visuo-tactile Dynamics and Perception of Deformable Objects},
publisher = {arXiv},
year = {2022},
}
Related Articles
- VIRDO: Visio-tactile Implicit Representations of Deformable Objects, Youngsun Wi et. al., ICRA’22